We have been very productive this year already! Five new NERDS publications are released this week:
- , by M. Coscia, published in EPJ Data Science
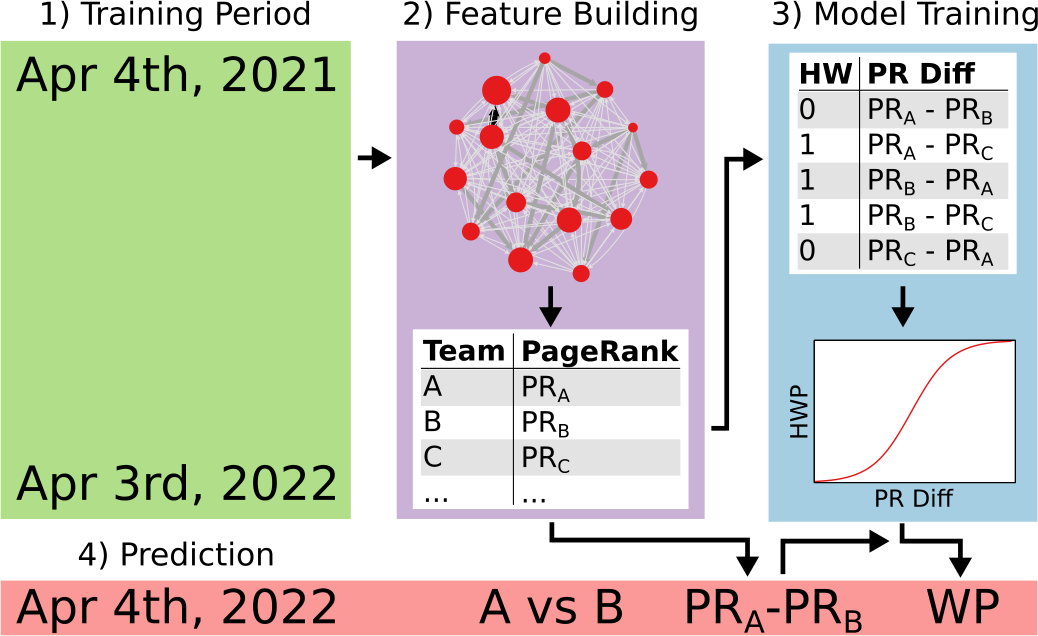
We analyze more than 300,000 professional sports matches in the 1996-2023 period from nine disciplines, to identify which disciplines are getting more/less predictable over time. We investigate the home advantage effect, since it can affect outcome predictability and it has been impacted by the COVID-19 pandemic. Going beyond previous work, we estimate which sport management model – between the egalitarian one popular in North America and the rich-get-richer used in Europe – leads to more uncertain outcomes. Our results show that there is no generalized trend in predictability across sport disciplines, that home advantage has been decreasing independently from the pandemic, and that sports managed with the egalitarian North American approach tend to be less predictable. We base our result on a predictive model that ranks team by analyzing the directed network of who-beats-whom, where the most central teams in the network are expected to be the best performing ones.
- Algorithmic Fairness: Learnings From a Case That Used AI For Decision Support, by V. Sekara, T.S. Skadegard Thorsen, and R. Sinatra, published by the Crown Princess Mary Center
This policy brief provides a small introduction to algorithmic fairness and an example of auditing fairness in an algorithm which was aimed at identifying and assessing children at risk from abuse.
-
The Parrot Dilemma: Human-Labeled vs. LLM-augmented Data in Classification Tasks, by A.G. Møller, J.A. Dalsgaard, A. Pera, L.M. Aiello (accepted at EACL’24).
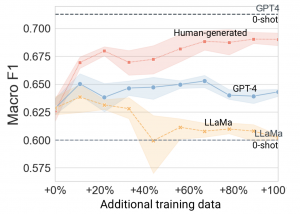
How good are Large Language Models in generating synthetic examples for training classifiers? To find out, we used GPT4 and Llama2 to augment existing training sets for typical Computational Social Science tasks. Our experiments show that the time to replace human-generated training data with LLMs has yet to come: human-generated text and labels provide more valuable information during training for most tasks. However, artificial data augmentation can add value when encountering extremely rare classes in multi-class scenarios, as finding new examples in real-world data can be challenging. -
Shifting Climates: Climate Change Communication from YouTube to TikTok, by A. Pera, L.M. Aiello (accepted at WebSci’24).

How do video content creators tailor their communication strategies in the era of short-form content? We conducted a comparative study of the YouTube and TikTok video productions of 21 prominent climate communicators active on both platforms. We found that when using TikTok, creators use a more emotionally resonant, self-referential, and action-oriented language compared to YouTube. Also, the response of the public aligns more closely to the tone of the videos in TikTok.
- The role of interface design on prompt-mediated creativity in Generative AI, by M. Torricelli, M. Martino, A. Baronchelli, L.M. Aiello (accepted at WebSci’24).
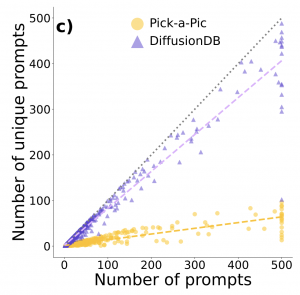
We analyze 145k+ user prompts from two Generative AI platforms for image generation to see how people explore new concepts over time, and how their exploration might be influenced by different design choices in human-computer interfaces to Generative AI. We find that creativity in prompts declines when the interface provides generation shortcuts that deviate the user attention from prompting.