
Right-wing Votes Relate to Delays in Bicycle Network Development, by C. Sebastiao & M. Szell, published in Findings
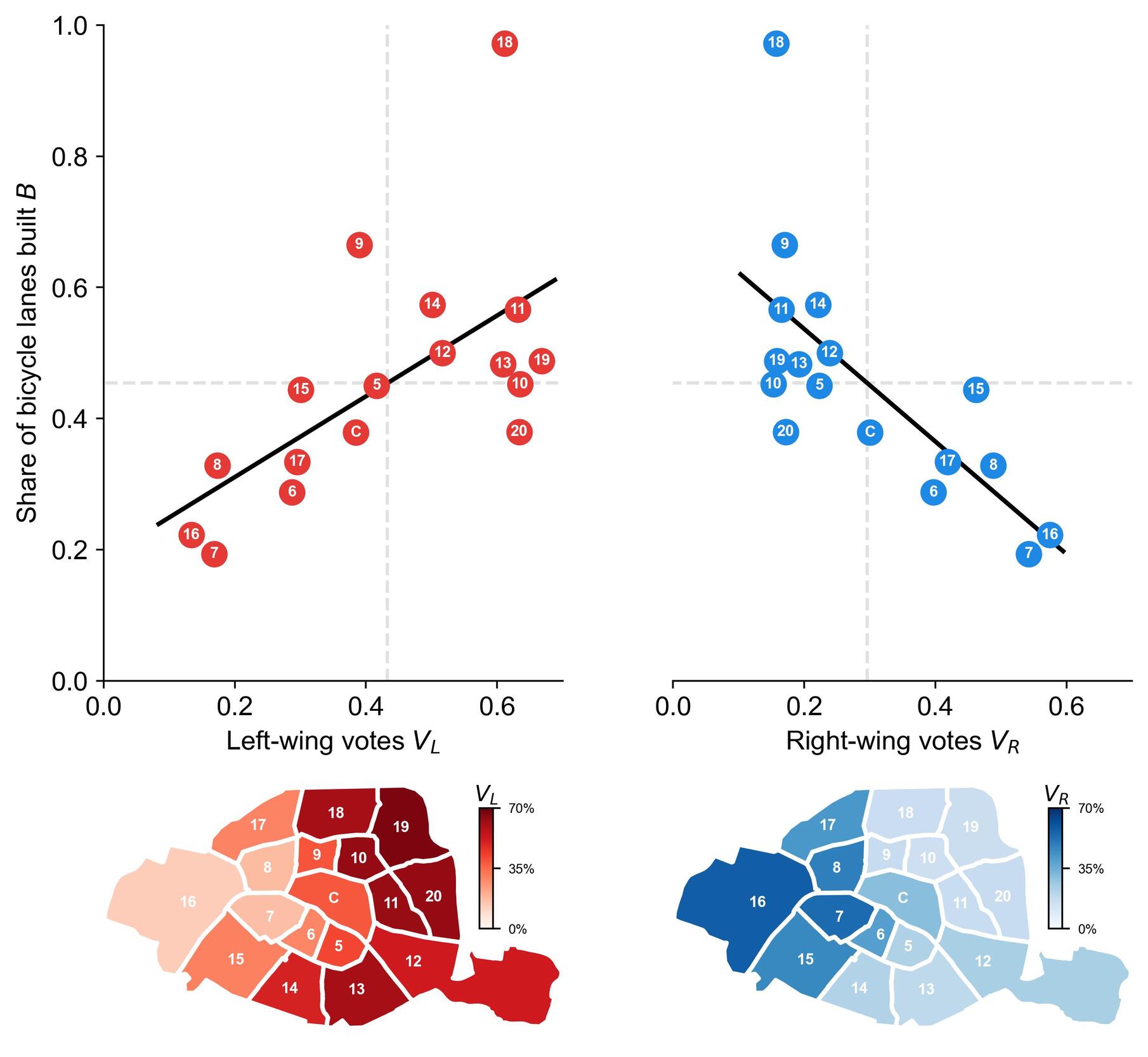
Paris has implemented only 43% of its 2021-2026 bicycle network plan by its 2026 deadline, but the delays are not equally distributed. Correlating political voting and bicycle infrastructure data, we find that boroughs with a higher share of right-wing votes are also boroughs with the largest delays in bicycle infrastructure development. Although the number of voting units is only 17, this correlation is remarkably strong and significant. At the city scale, for each additional 1% of right-wing votes, we find 0.86% less protected bicycle lanes built.
New NERDS publication on fairness of human-AI collaboration in candidate recommendation
Human, Algorithm, or Both? Gender Bias in Human-Augmented Recruiting, by Mesut Kaya & Toine Bogers, published in FAccT ’26: The 2026 ACM Conference on Fairness, Accountability, and Transparency
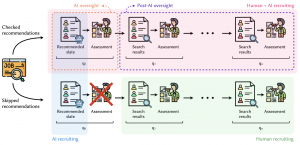
Recent years have seen rapid growth in the market for HR technology and AI-driven HR solutions in particular. This popularity has also resulted in increased attention to the negative aspects of using AI to support hiring practices, such as the risk of reinforcing existing biases against vulnerable groups based on gender or other sensitive attributes. Combining human experience with AI efficiency in making recruiting and selection decisions has the potential to help mitigate these biases, but despite a considerable amount of research on fairness in algorithmic hiring, actual empirical evaluations comparing the fairness of human, AI, and human-augmented decision-making remain scarce. In this study, we address this gap by presenting a quantitative analysis of gender bias across three scenarios of a real-world recruitment platform: (1) recruiters searching a CV database manually for relevant candidates, (2) AI-driven matching between candidates and jobs, and (3) a combination of human and AI-driven recruiting. We find that human recruiters produce lists of candidates that are fairer in terms of gender than the AI-only solution, with more deliberation by humans resulting in fairer outcomes. However, the combination of human and AI-driven is more than the sum of its parts and produces the fairest candidate lists: interacting with the slate of recommended candidates first before manually searching for additional candidates has a beneficial effect on the gender fairness of the set of candidates that are viewed, clicked, and contacted afterwards. Our work provides one of the first empirical comparisons of fairness across human, AI, and hybrid recruiting processes, offering evidence to inform the development of more equitable hiring practices and highlighting the importance of human oversight for mitigating bias in algorithmic hiring.
New NERDS paper on drug traffic and migration
Displacement and disconnection: the impact of violence on migration networks and highway traffic in Mexico, by M. Coscia & R. Gutiérrez-Romero, published in Spatial Economic Analysis.

This paper examines how violence impacts migration flows and the strength of migration networks across Mexico’s 2454 municipalities. Using a novel network algorithm and census data from 2005 to 2020, we detect structural changes in domestic and international migration beyond what net flows reveal. To identify causal effects, homicide rates are instrumented using variation in fuel prices and municipal distance to fuel pipelines, capturing exogenous shocks from large-scale fuel theft. Rising violence led to 1.12 million additional domestic emigrants, 50,200 fewer returnees from the United States, stronger emigration networks and reduced highway traffic linking violent areas to the rest of the country.
NERDS at CS2Italy 2026 in Torino

NERDS has contributed massively to the CS2Italy conference held in Torino this week. Roberta Sinatra delivered a keynote on “Science of Science in the Age of AI”. Arianna Pera and Elisabetta Salvai gave plenary presentations on visual cultural norms and algorithmic fairness. Many other members gave 12 presentations in parallel sessions about Gender Disparities , LLM agents, Climate narratives, and much more. We are already warming up for CS2Nordics, the incoming Nordic chapter of this conference series.
We have successfully held our first retreat
With NERDS hitting 7 years old and growing over 30 people, it has been long overdue to hold our first retreat. We did so last week at the AI Pioneer Center, in the old astronomic observatory inside Copenhagen’s beautiful botanic garden (plus awesome dinner at Food Club Nørrebro), organized by Jonas, Jan, and Toine.

The retreat was a wonderful event that deepened our social ties, where we learned much more about each other, and discussed what works well or what does not work so well at NERDS.
On all levels, from fac ulties to long-term NERDS and visitors, we identified issues we want to improve, including diversity and hiring, more internal exchange, website updates, or more formalized tasks with ownership (and PhD duty credits). It was great to see though that we do not have any serious social issues – to the contrary, the retreat was a confirmation of how well we all get along, and how nice a research group can be. ❤️
ulties to long-term NERDS and visitors, we identified issues we want to improve, including diversity and hiring, more internal exchange, website updates, or more formalized tasks with ownership (and PhD duty credits). It was great to see though that we do not have any serious social issues – to the contrary, the retreat was a confirmation of how well we all get along, and how nice a research group can be. ❤️
In the coming weeks we are going to get to work to implement the short-term-implementable issues, keep pushing for improving our long-term issues to make NERDS an even better place, and definitely aim to make the NERDS retreat a recurring experience!




Ariel Avanzi has joined NERDS

Ariel joins us as a new Research Assistant. With his background in the physics of complex systems, he will work with Jonas L. Juul on quantifying how networks change.
One important application of Ariel’s work could be in the shipping industry, and the project is funded by two maritime foundations: Orient’s Fund and the Danish Maritime Fund.
We are thrilled to have you on board, Ariel.
Ahoy!
New NERDS publication on transport network growth
The trade-off between directness and coverage in transport network growth, by C. Sebastiao, A. Vybornova, A.R. Vierø, L.M. Aiello & M. Szell, published in Applied Network Science

We systematically study the growth of connected planar networks, quantifying functionality of the growing network structure. We compare random growth with various greedy and human-designed, manual growth strategies. We evaluate our results via the fundamental performance metrics of directness and coverage, finding non-trivial trade-offs between them. Manual strategies fare better than greedy strategies on both metrics, while random strategies perform worst and are unlikely to be Pareto efficient. Centrality-based greedy strategies tend to perform best for directness but are worse than random strategies for coverage, while coverage-based greedy strategies can achieve maximum global coverage as fast as possible but perform as poorly for directness as random strategies. Directness-based greedy strategies get stuck in local optimum traps. These results hold for a number of stylized urban transport network topologies. Our insights are crucial for applications where the order in which links are added to a spatial network is important, such as in urban or regional transport network design problems.
Two New NERDS Papers: Politician Campaigns; and Money Laundering
We have two new publications out!
- Disconnect between the public face and the voting behavior of political representatives by Christian Ivert Andersen and Michele Coscia, published in the journal Applied Network Science.
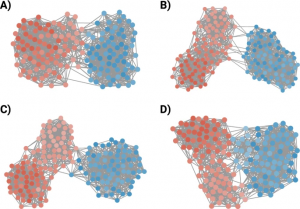
One of representative democracy’s tenets is that a political candidate runs on a specific platform, which is information the electorate uses to determine whether to vote for them or not. If this promise is to be maintained, it is fundamental that the public face candidates present corresponds to their actions in parliament once elected. Such a promise has been put in question both by scholars, but also by the electorate. In different countries at different times, the people have expressed various degrees of dissatisfaction with democracy: often the feeling is that representatives put their own interests—or the interest of a powerful minority—before the ones of their constituencies. In this paper, we propose a network-based quantitative investigation of this disconnect between the public face and the voting behavior of elected representatives. By using data from Denmark, we can place politicians in two different spaces, determined by their electoral campaign promises on the one hand, and on the other hand by the votes they cast in parliament. We find that our technique makes it possible both to find clear, expected, and consistent left-right divides between the political parties; as well as a larger-than-expected disconnect between the public face and the voting behavior. Our preliminary results indicate that the aggregate voting behavior in parliament of politicians does not match with how they present themselves to the public on the salient issues discussed during the election campaign. - Evaluating fraud detection algorithms in a decentralized scenario by Ada M Gige, Lasse Buschmann Alsbirk, Michele Coscia, published in the journal Royal Society Open Science.
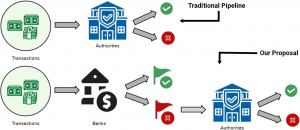
Financial fraud is an umbrella term including a vast number of illegal activities. These activities involve a significant fraction of the global economy. Traditional investigation techniques are labour-intensive and cannot scale to match the size of the issue. Machine learning has provided effective tools which deliver high accuracy in identifying transactions that could be involved in fraudulent activities. In this paper, we point out that the state-of-the-art in financial fraud detection has been applied to the unrealistic scenario of an omniscient centralized global authority which has access to all bank transactions globally. We propose a more realistic evaluation scenario, one made of two steps: first, the bank flags its own transactions using exclusively information it possesses; then only flagged transactions from all banks are analysed by the governmental authority for potential prosecution. We find that, in such a realistic scenario, the effectiveness of the state-of-the-art method for financial fraud detection decreases. Moreover, we show that in this decentralized scenario, it pays off to use simpler methods than the state-of-the-art, depending on the specific objective function the system wants to ensure.
New NERDS publication on candidate recommendation
Analyzing the Effects of a Human-in-the-Loop Candidate Recommendation Algorithm at Jobindex, by Mesut Kaya & Toine Bogers, published in ACM Transactions on Recommender Systems
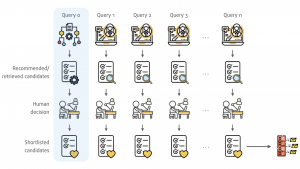
Recruiting is the process of assessing relevant candidates for an open position based on their education, work experience, and knowledge, skills, and abilities. As part of a collaborative project between academia and industry, we developed an automated candidate recommendation system to support recruiters in this time-consuming task of matching CVs to job postings. We chronicle the development and deployment of a candidate recommender system at Jobindex, expanding our focus from a pure machine learning problem to a holistic overview of the development and deployment of such a system in a real-world setting. After extensive offline and online experimentation, we integrated our algorithm into the recruiters’ everyday workflow. Our second contribution is a detailed analysis of how these recruiters have adopted this candidate recommender system, and which factors influence their engagement with the slate of suggested candidates. In this article, we present the results of 17 months of data (corresponding to 41,390 jobs) and show how engaging with these recommendations has impacted the recruiters’ work, and which factors influence their task success. While adoption of the new system was initially hindered by deeply-ingrained habits and a lack of trust in AI, over time the combination of human and automated recruitment shows considerable promise across a variety of job and recruiter characteristics.
Two new NERDS papers: data storytelling visualization, LLMs for complex information needs
We have two new publications out!
- The Influence of the Communication Medium on Data Storytelling, by Tamara Nagel and Toine Bogers published in CHIIR ’26: Proceedings of the 2026 ACM Conference on Human Information Interaction and Retrieval 2026

Despite increasing interest in data storytelling, it remains unclear how the choice of communication medium shapes its effectiveness, particularly for audiences with varying levels of data literacy. This paper reports on a controlled, longitudinal experiment comparing verbal to written storytelling alongside a baseline data visualization condition. Each condition employed simple graphs and an author-driven narrative to examine their effects on recall and attitude change. Results showed mixed results of data storytelling: while storytelling did not improve recall, verbal storytelling and no storytelling facilitated long-term attitude change, whereas written storytelling did not. Higher data literacy supported long-term recall but was associated with smaller immediate attitude shifts, an effect that diminished over time. These findings challenge assumptions about the universal advantages of narrative-based communication, demonstrating that medium, topic familiarity, and audience characteristics jointly determine outcomes. The study contributes empirical evidence to the field and calls for further research into how narrative structures and visualization complexity affect the effectiveness of data storytelling. - Tip-of-the-Tongue Search in the Wild: Analyzing Human and LLM Performance and Success Factors on Complex Search Requests, by Toine Bogers, Maria Gäde, Mark Hall, Marijn Koolen, Vivien Petras, and Mette Skov, published in CHIIR ’26: Proceedings of the 2026 ACM Conference on Human Information Interaction and Retrieval 2026
 Users often turn to online forums when searching for known books, movies, or games that they cannot identify through conventional search engines. These “tip-of-the tongue” requests present a unique challenge, appearing highly variable in formulation, context, and specificity. So far, these could mostly only be solved by other humans answering in forums. Generative AI is believed to help solve these specific questions. In this work, we manually annotated 150 requests each for books, games, and movies in the casual leisure domain to study the differences between solved and unsolved requests and identify factors that influence their difficulty. We compare human responses in forum threads with the performance of a Large Language Model (LLM) under similar conditions. Specifically, we investigate how the formulation of requests affects human and LLM success; how item properties impact LLM retrieval; how interaction and feedback within a thread shape human and LLM performance; and whether increasing the information provided to an LLM improves its chances of solving the request. Our findings offer new insights into what makes these known-item search problems easier or harder to solve. This study contributes to a better understanding of complex search behavior and the role of LLMs in helping with difficult casual-leisure information needs.
Users often turn to online forums when searching for known books, movies, or games that they cannot identify through conventional search engines. These “tip-of-the tongue” requests present a unique challenge, appearing highly variable in formulation, context, and specificity. So far, these could mostly only be solved by other humans answering in forums. Generative AI is believed to help solve these specific questions. In this work, we manually annotated 150 requests each for books, games, and movies in the casual leisure domain to study the differences between solved and unsolved requests and identify factors that influence their difficulty. We compare human responses in forum threads with the performance of a Large Language Model (LLM) under similar conditions. Specifically, we investigate how the formulation of requests affects human and LLM success; how item properties impact LLM retrieval; how interaction and feedback within a thread shape human and LLM performance; and whether increasing the information provided to an LLM improves its chances of solving the request. Our findings offer new insights into what makes these known-item search problems easier or harder to solve. This study contributes to a better understanding of complex search behavior and the role of LLMs in helping with difficult casual-leisure information needs.