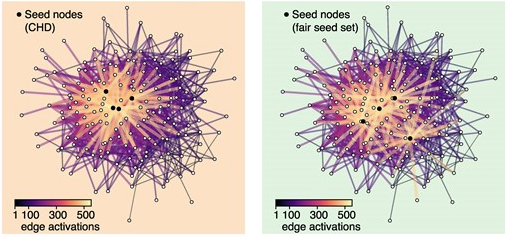
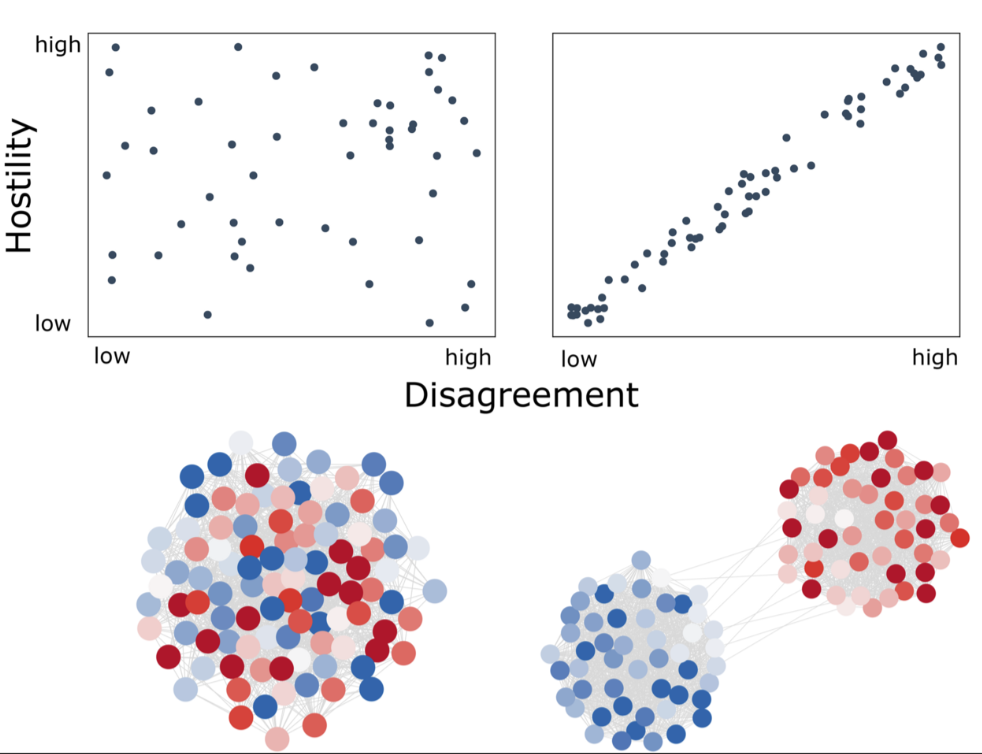
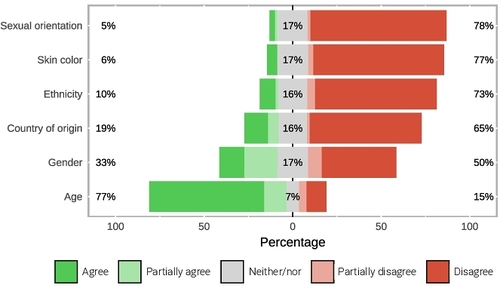
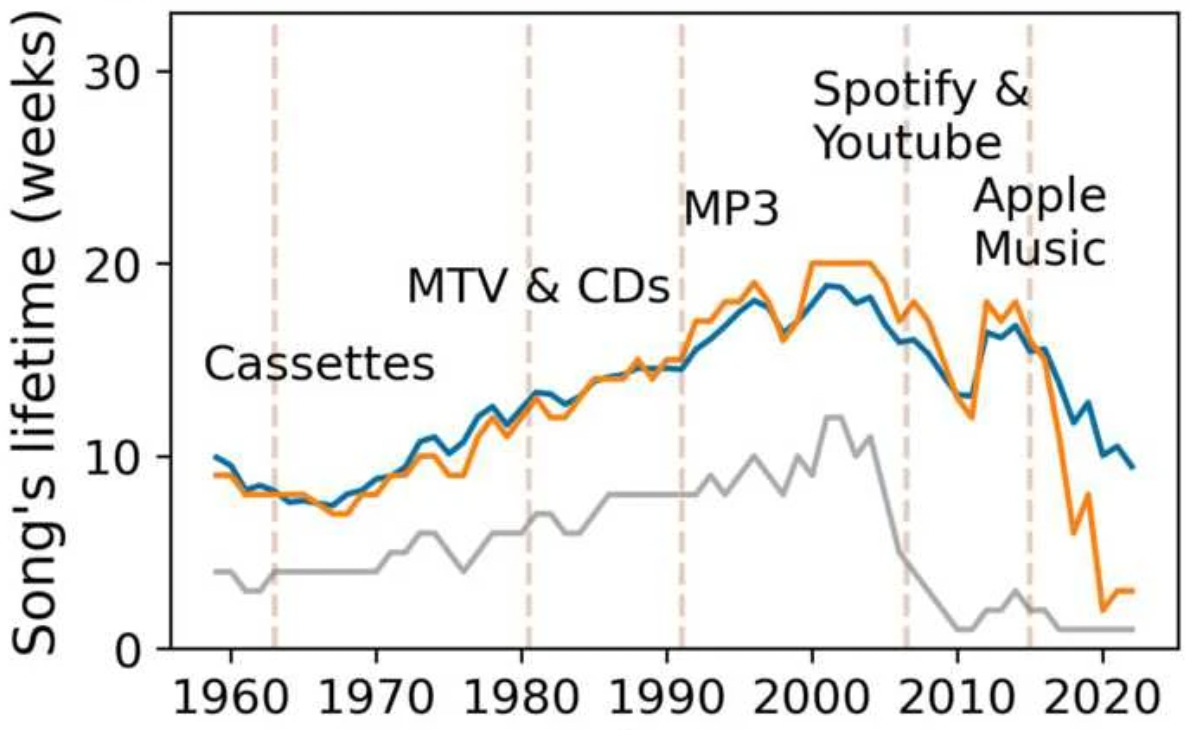
Displacement and disconnection: the impact of violence on migration networks and highway traffic in Mexico, by M. Coscia & R. Gutiérrez-Romero, published in Spatial Economic Analysis.

This paper examines how violence impacts migration flows and the strength of migration networks across Mexico’s 2454 municipalities. Using a novel network algorithm and census data from 2005 to 2020, we detect structural changes in domestic and international migration beyond what net flows reveal. To identify causal effects, homicide rates are instrumented using variation in fuel prices and municipal distance to fuel pipelines, capturing exogenous shocks from large-scale fuel theft. Rising violence led to 1.12 million additional domestic emigrants, 50,200 fewer returnees from the United States, stronger emigration networks and reduced highway traffic linking violent areas to the rest of the country.

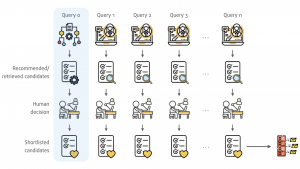

 Users often turn to online forums when searching for known books, movies, or games that they cannot identify through conventional search engines. These “tip-of-the tongue” requests present a unique challenge, appearing highly variable in formulation, context, and specificity. So far, these could mostly only be solved by other humans answering in forums. Generative AI is believed to help solve these specific questions. In this work, we manually annotated 150 requests each for books, games, and movies in the casual leisure domain to study the differences between solved and unsolved requests and identify factors that influence their difficulty. We compare human responses in forum threads with the performance of a Large Language Model (LLM) under similar conditions. Specifically, we investigate how the formulation of requests affects human and LLM success; how item properties impact LLM retrieval; how interaction and feedback within a thread shape human and LLM performance; and whether increasing the information provided to an LLM improves its chances of solving the request. Our findings offer new insights into what makes these known-item search problems easier or harder to solve. This study contributes to a better understanding of complex search behavior and the role of LLMs in helping with difficult casual-leisure information needs.
Users often turn to online forums when searching for known books, movies, or games that they cannot identify through conventional search engines. These “tip-of-the tongue” requests present a unique challenge, appearing highly variable in formulation, context, and specificity. So far, these could mostly only be solved by other humans answering in forums. Generative AI is believed to help solve these specific questions. In this work, we manually annotated 150 requests each for books, games, and movies in the casual leisure domain to study the differences between solved and unsolved requests and identify factors that influence their difficulty. We compare human responses in forum threads with the performance of a Large Language Model (LLM) under similar conditions. Specifically, we investigate how the formulation of requests affects human and LLM success; how item properties impact LLM retrieval; how interaction and feedback within a thread shape human and LLM performance; and whether increasing the information provided to an LLM improves its chances of solving the request. Our findings offer new insights into what makes these known-item search problems easier or harder to solve. This study contributes to a better understanding of complex search behavior and the role of LLMs in helping with difficult casual-leisure information needs.