
Human, Algorithm, or Both? Gender Bias in Human-Augmented Recruiting, by Mesut Kaya & Toine Bogers, published in FAccT ’26: The 2026 ACM Conference on Fairness, Accountability, and Transparency
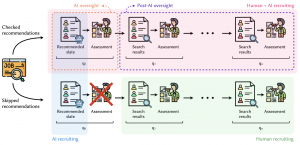
Recent years have seen rapid growth in the market for HR technology and AI-driven HR solutions in particular. This popularity has also resulted in increased attention to the negative aspects of using AI to support hiring practices, such as the risk of reinforcing existing biases against vulnerable groups based on gender or other sensitive attributes. Combining human experience with AI efficiency in making recruiting and selection decisions has the potential to help mitigate these biases, but despite a considerable amount of research on fairness in algorithmic hiring, actual empirical evaluations comparing the fairness of human, AI, and human-augmented decision-making remain scarce. In this study, we address this gap by presenting a quantitative analysis of gender bias across three scenarios of a real-world recruitment platform: (1) recruiters searching a CV database manually for relevant candidates, (2) AI-driven matching between candidates and jobs, and (3) a combination of human and AI-driven recruiting. We find that human recruiters produce lists of candidates that are fairer in terms of gender than the AI-only solution, with more deliberation by humans resulting in fairer outcomes. However, the combination of human and AI-driven is more than the sum of its parts and produces the fairest candidate lists: interacting with the slate of recommended candidates first before manually searching for additional candidates has a beneficial effect on the gender fairness of the set of candidates that are viewed, clicked, and contacted afterwards. Our work provides one of the first empirical comparisons of fairness across human, AI, and hybrid recruiting processes, offering evidence to inform the development of more equitable hiring practices and highlighting the importance of human oversight for mitigating bias in algorithmic hiring.
Author Archives: tobo
New NERDS publication on candidate recommendation
Analyzing the Effects of a Human-in-the-Loop Candidate Recommendation Algorithm at Jobindex, by Mesut Kaya & Toine Bogers, published in ACM Transactions on Recommender Systems
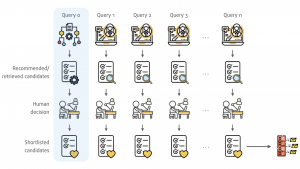
Recruiting is the process of assessing relevant candidates for an open position based on their education, work experience, and knowledge, skills, and abilities. As part of a collaborative project between academia and industry, we developed an automated candidate recommendation system to support recruiters in this time-consuming task of matching CVs to job postings. We chronicle the development and deployment of a candidate recommender system at Jobindex, expanding our focus from a pure machine learning problem to a holistic overview of the development and deployment of such a system in a real-world setting. After extensive offline and online experimentation, we integrated our algorithm into the recruiters’ everyday workflow. Our second contribution is a detailed analysis of how these recruiters have adopted this candidate recommender system, and which factors influence their engagement with the slate of suggested candidates. In this article, we present the results of 17 months of data (corresponding to 41,390 jobs) and show how engaging with these recommendations has impacted the recruiters’ work, and which factors influence their task success. While adoption of the new system was initially hindered by deeply-ingrained habits and a lack of trust in AI, over time the combination of human and automated recruitment shows considerable promise across a variety of job and recruiter characteristics.
Two new NERDS papers: data storytelling visualization, LLMs for complex information needs
We have two new publications out!
- The Influence of the Communication Medium on Data Storytelling, by Tamara Nagel and Toine Bogers published in CHIIR ’26: Proceedings of the 2026 ACM Conference on Human Information Interaction and Retrieval 2026

Despite increasing interest in data storytelling, it remains unclear how the choice of communication medium shapes its effectiveness, particularly for audiences with varying levels of data literacy. This paper reports on a controlled, longitudinal experiment comparing verbal to written storytelling alongside a baseline data visualization condition. Each condition employed simple graphs and an author-driven narrative to examine their effects on recall and attitude change. Results showed mixed results of data storytelling: while storytelling did not improve recall, verbal storytelling and no storytelling facilitated long-term attitude change, whereas written storytelling did not. Higher data literacy supported long-term recall but was associated with smaller immediate attitude shifts, an effect that diminished over time. These findings challenge assumptions about the universal advantages of narrative-based communication, demonstrating that medium, topic familiarity, and audience characteristics jointly determine outcomes. The study contributes empirical evidence to the field and calls for further research into how narrative structures and visualization complexity affect the effectiveness of data storytelling. - Tip-of-the-Tongue Search in the Wild: Analyzing Human and LLM Performance and Success Factors on Complex Search Requests, by Toine Bogers, Maria Gäde, Mark Hall, Marijn Koolen, Vivien Petras, and Mette Skov, published in CHIIR ’26: Proceedings of the 2026 ACM Conference on Human Information Interaction and Retrieval 2026
 Users often turn to online forums when searching for known books, movies, or games that they cannot identify through conventional search engines. These “tip-of-the tongue” requests present a unique challenge, appearing highly variable in formulation, context, and specificity. So far, these could mostly only be solved by other humans answering in forums. Generative AI is believed to help solve these specific questions. In this work, we manually annotated 150 requests each for books, games, and movies in the casual leisure domain to study the differences between solved and unsolved requests and identify factors that influence their difficulty. We compare human responses in forum threads with the performance of a Large Language Model (LLM) under similar conditions. Specifically, we investigate how the formulation of requests affects human and LLM success; how item properties impact LLM retrieval; how interaction and feedback within a thread shape human and LLM performance; and whether increasing the information provided to an LLM improves its chances of solving the request. Our findings offer new insights into what makes these known-item search problems easier or harder to solve. This study contributes to a better understanding of complex search behavior and the role of LLMs in helping with difficult casual-leisure information needs.
Users often turn to online forums when searching for known books, movies, or games that they cannot identify through conventional search engines. These “tip-of-the tongue” requests present a unique challenge, appearing highly variable in formulation, context, and specificity. So far, these could mostly only be solved by other humans answering in forums. Generative AI is believed to help solve these specific questions. In this work, we manually annotated 150 requests each for books, games, and movies in the casual leisure domain to study the differences between solved and unsolved requests and identify factors that influence their difficulty. We compare human responses in forum threads with the performance of a Large Language Model (LLM) under similar conditions. Specifically, we investigate how the formulation of requests affects human and LLM success; how item properties impact LLM retrieval; how interaction and feedback within a thread shape human and LLM performance; and whether increasing the information provided to an LLM improves its chances of solving the request. Our findings offer new insights into what makes these known-item search problems easier or harder to solve. This study contributes to a better understanding of complex search behavior and the role of LLMs in helping with difficult casual-leisure information needs.