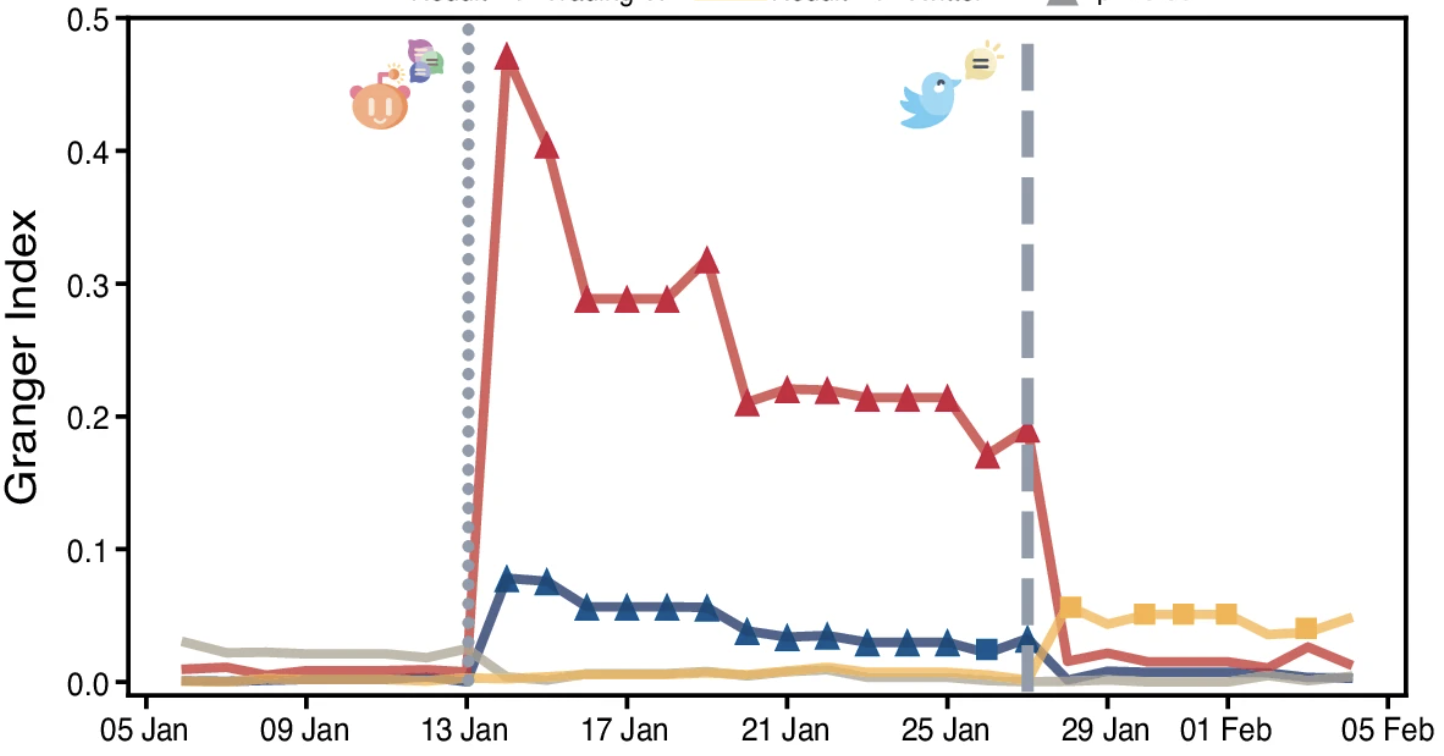
We have a big paper out today, long time in the making, led by Yanmeng Xin, our long-term PhD student visitor in 2021-2023, co-authored by Roberta Sinatra, just published in Nature Human Behavior: Academic mentees thrive in big groups, but survive in small groups, by Y. Xing, Y Ma, Y. Fan, R. Sinatra, and A. Zeng.
The main message of the paper is intriguing: If you “grow up” in a big research group, and if you survive, you will have high success. At the same time, in a big group it is also harder to survive, especially if your mentor is very productive. So what is then good mentorship, and what is a good group to be?
Interestingly, at NERDS we are a fairly big research group, but with several mentors who are by themselves not too busy, so we combine the best of both worlds 😁 In fact, this paper itself is another one in a long series of success stories where a visitor accomplished something great while staying at our ✨🦄 ~enchanted NERDS grounds~ 🧚♂️✨ in Copenhagen. (“NERDS is one of the best places I have ever stayed.”)
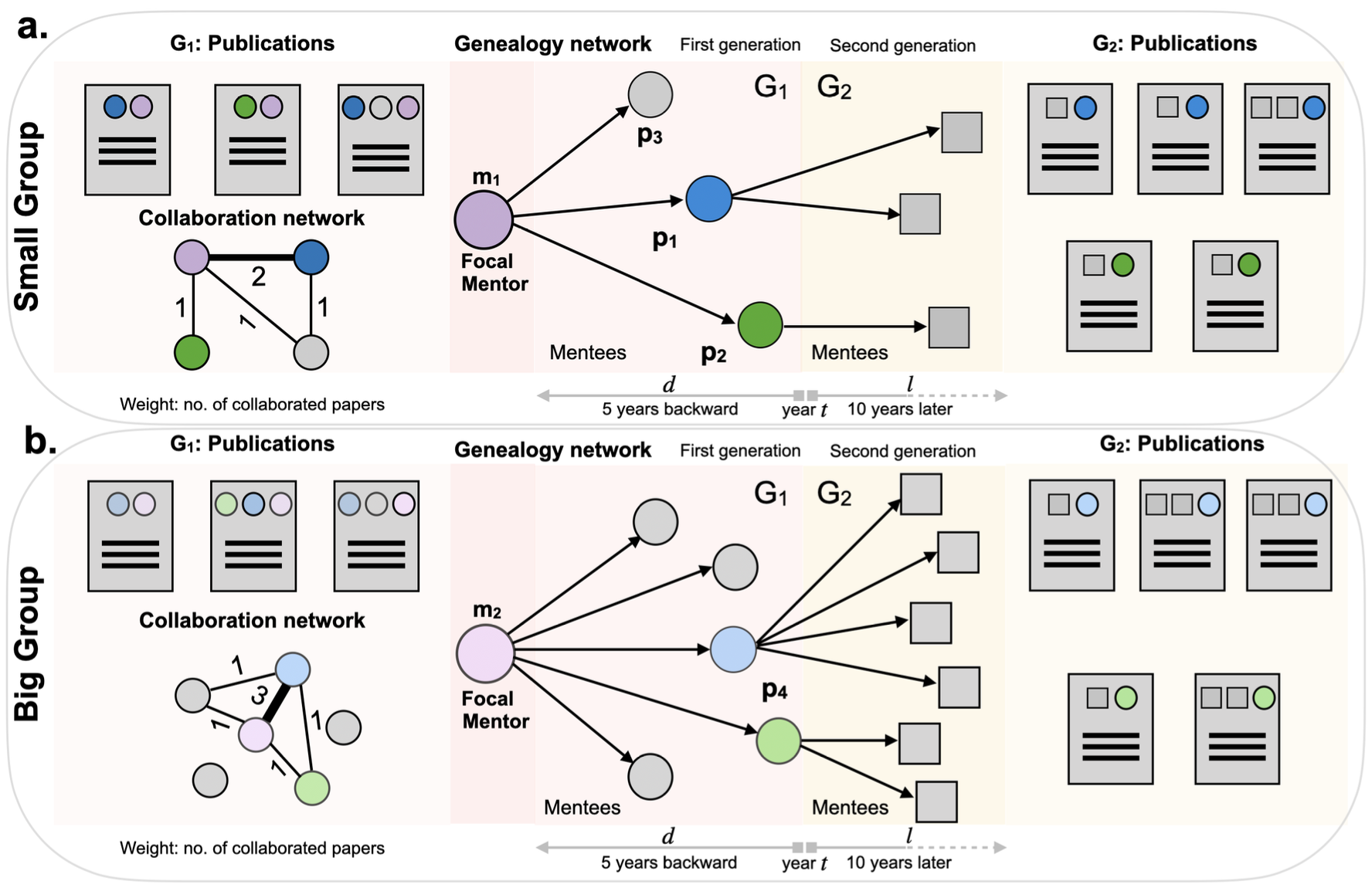
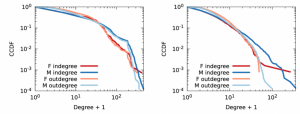
Mentoring is a key component of scientific achievements, contributing to overall measures of career success for mentees and mentors. Within the scientific community, possessing a large research group is often perceived as an indicator of exceptional mentorship and high-quality research. However, such large, competitive groups may also escalate dropout rates, particularly among early-career researchers. Overly high dropout rates of young researchers may lead to severe postdoc shortage and loss of top-tier academics in contemporary academia. In this context, we collect longitudinal genealogical data on mentor-mentee relations and their publication, and analyze the influence of a mentor’s group size on the future academic longevity and performance of their mentees. Our findings indicate that mentees trained in larger groups tend to exhibit superior academic performance compared to those from smaller groups, provided they remain in academia post-graduation. However, we also observe two surprising patterns: Academic survival rate is significantly lower for (1) mentees from larger groups, and for (2) mentees with more productive mentors. The trend is verified in institutions of different prestige. These findings highlight a negative correlation between a mentor’s success and the academic survival rate of their mentees, prompting a rethinking of effective mentorship and offering actionable insights for career advancement.
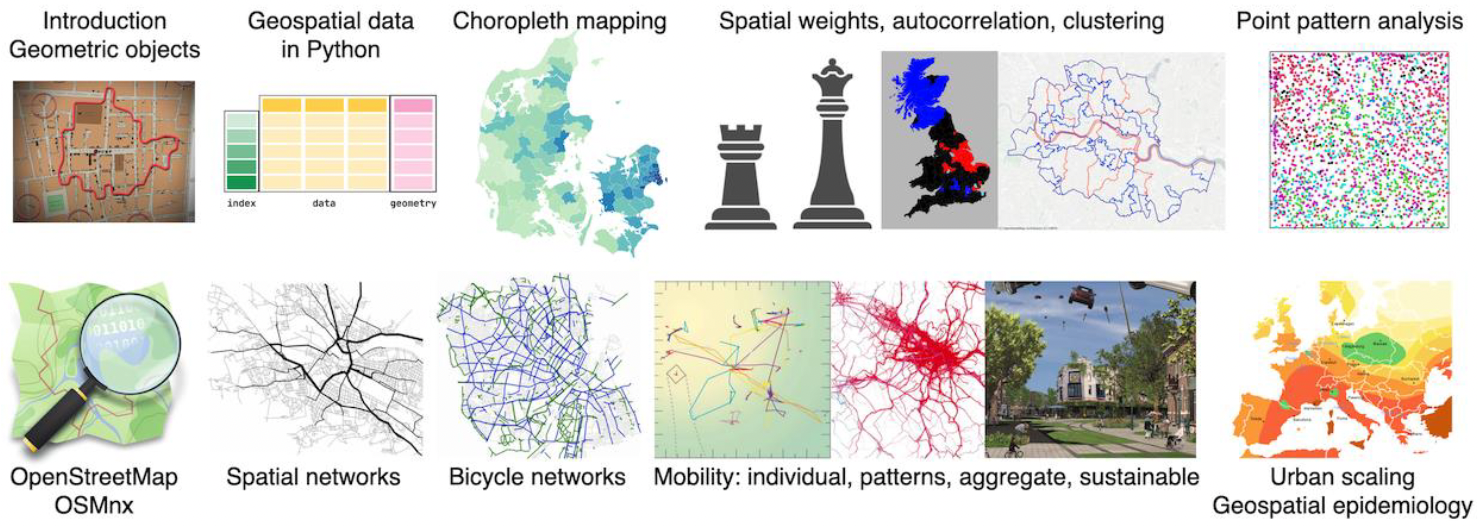
 NERDS member Michele Coscia has updated his textbook for the Network Analysis and Advanced Network Science classes he teaches at ITU. This “Atlas for the Aspiring Network Scientist”, has now reached version 2.0, and 916 pages, and is available for anyone to read for free:
NERDS member Michele Coscia has updated his textbook for the Network Analysis and Advanced Network Science classes he teaches at ITU. This “Atlas for the Aspiring Network Scientist”, has now reached version 2.0, and 916 pages, and is available for anyone to read for free: